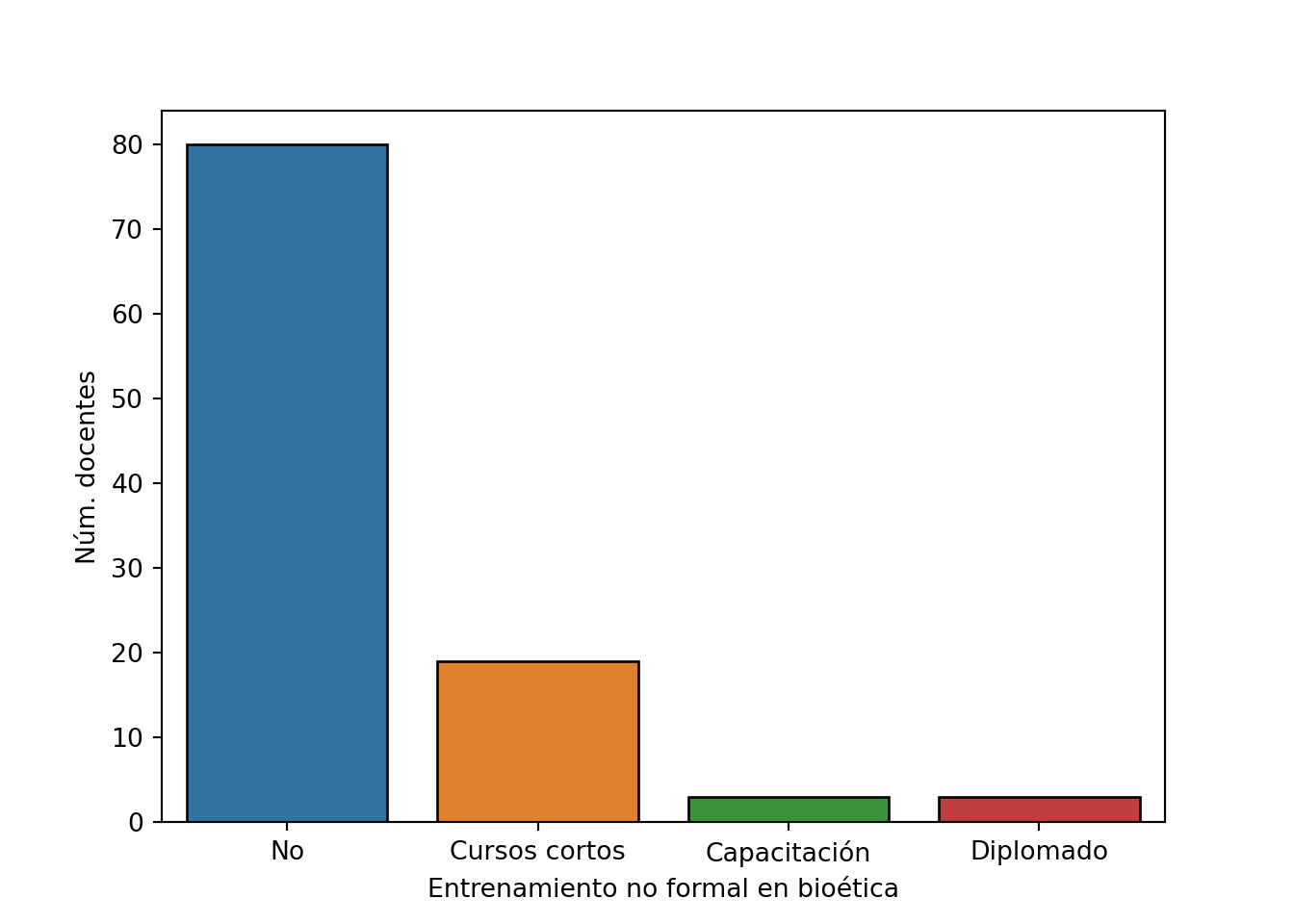
Entrenamiento no formal
entrenamiento = 'no_formal'
etiqueta = 'Entrenamiento no formal en bioética'
df[entrenamiento].value_counts(sort=False)
## No 80
## Cursos cortos 19
## Capacitación 3
## Diplomado 3
## Name: no_formal, dtype: int64
df[entrenamiento].value_counts(sort=False, normalize=True).round(2)
## No 0.76
## Cursos cortos 0.18
## Capacitación 0.03
## Diplomado 0.03
## Name: no_formal, dtype: float64
sns.countplot(x=entrenamiento, data=df, edgecolor='black')
plt.xlabel(etiqueta)
plt.ylabel('Núm. docentes')
plt.show()
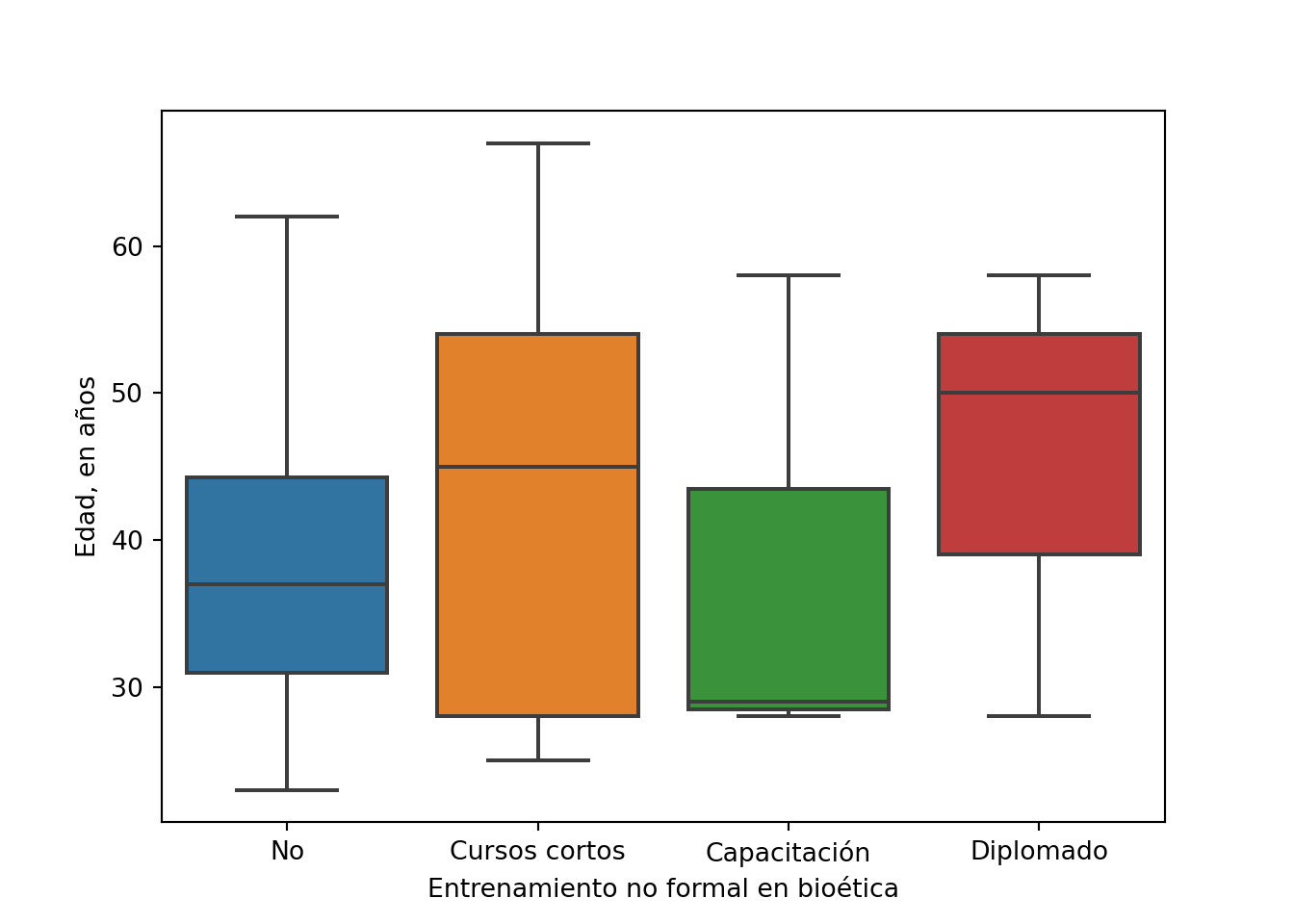
## vs edad
var = 'edad' # Definición de la variable de interés
df.groupby(entrenamiento)[var].describe().round().transpose() # Tendencia central y dispersión
## no_formal No Cursos cortos Capacitación Diplomado
## count 80.0 19.0 3.0 3.0
## mean 38.0 43.0 38.0 45.0
## std 9.0 14.0 17.0 16.0
## min 23.0 25.0 28.0 28.0
## 25% 31.0 28.0 28.0 39.0
## 50% 37.0 45.0 29.0 50.0
## 75% 44.0 54.0 44.0 54.0
## max 62.0 67.0 58.0 58.0
scipy.stats.kruskal(*[data[var].values for name, data in df.groupby(entrenamiento)]) # Prueba de Kruskal-Wallis
## KruskalResult(statistic=1.9126906406963458, pvalue=0.5907243163184515)
sns.boxplot(x=entrenamiento, y=var, data =df) # Gráfico de cajas
plt.xlabel(etiqueta)
plt.ylabel('Edad, en años')
plt.show()
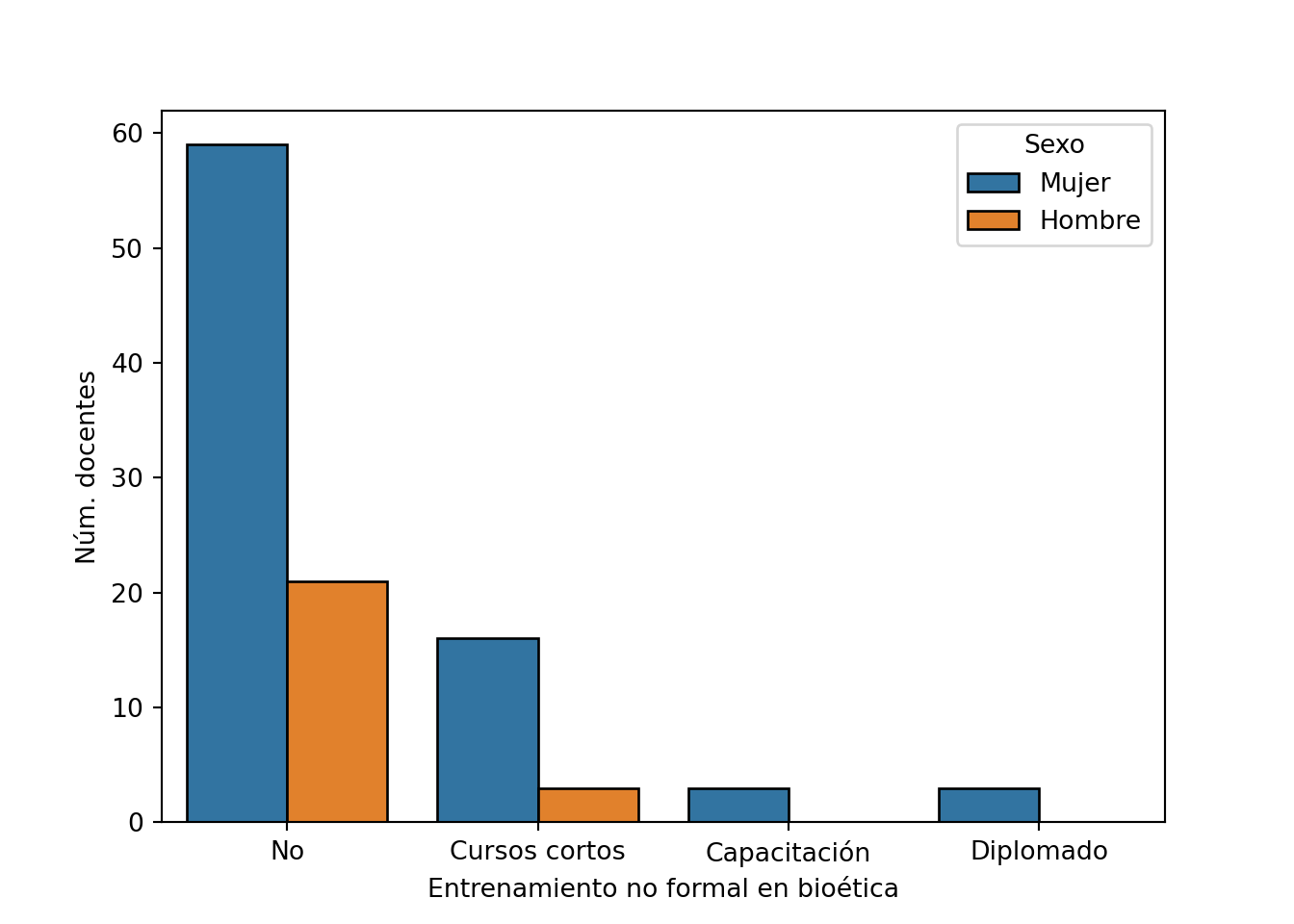
## vs sexo
var = 'sexo' # Definición de la variable de contraste
pd.crosstab(df[var], df[entrenamiento]) # Frecuencia absoluta
## no_formal No Cursos cortos Capacitación Diplomado
## sexo
## Hombre 21 3 0 0
## Mujer 59 16 3 3
pd.crosstab(df[var], df[entrenamiento], normalize='index').round(2) # Frecuencia relativa
## no_formal No Cursos cortos Capacitación Diplomado
## sexo
## Hombre 0.88 0.12 0.00 0.00
## Mujer 0.73 0.20 0.04 0.04
scipy.stats.chi2_contingency(pd.crosstab(df[entrenamiento], df[var])) # Prueba del chi-cuadrado
## (2.838313230994152, 0.4172316504679091, 3, array([[18.28571429, 61.71428571],
## [ 4.34285714, 14.65714286],
## [ 0.68571429, 2.31428571],
## [ 0.68571429, 2.31428571]]))
sns.countplot(x=entrenamiento, hue=var, data=df, edgecolor='black') # Gráfico de barras
plt.xlabel(etiqueta)
plt.ylabel('Núm. docentes')
plt.legend(title='Sexo', loc='upper right')
plt.show()
## vs grado académico
var = 'grado' # Definición de la variable de contraste
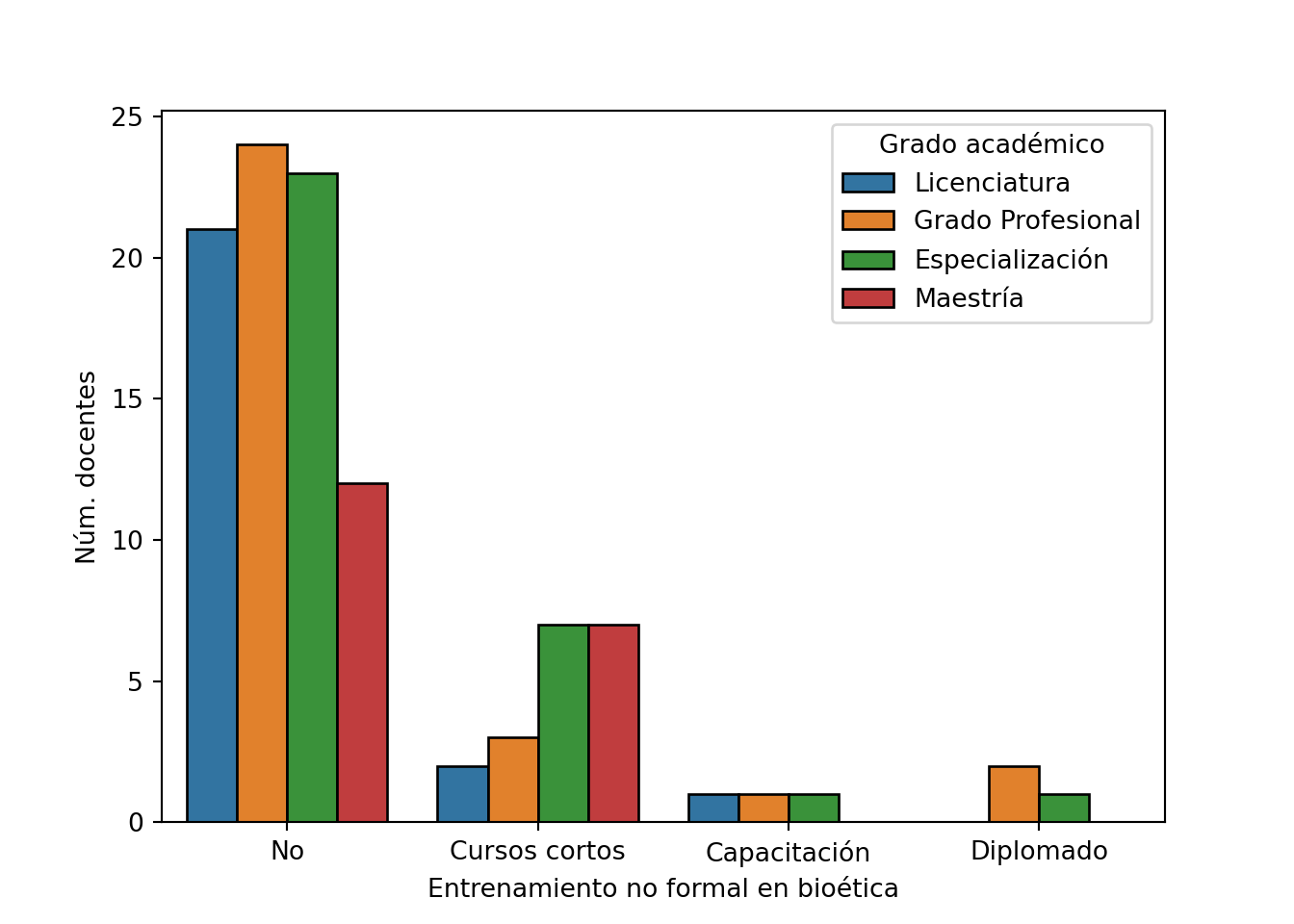
pd.crosstab(df[var], df[entrenamiento]) # Frecuencia absoluta
## no_formal No Cursos cortos Capacitación Diplomado
## grado
## Licenciatura 21 2 1 0
## Grado Profesional 24 3 1 2
## Especialización 23 7 1 1
## Maestría 12 7 0 0
pd.crosstab(df[var], df[entrenamiento], normalize='index').round(2) # Frecuencia relativa
## no_formal No Cursos cortos Capacitación Diplomado
## grado
## Licenciatura 0.88 0.08 0.04 0.00
## Grado Profesional 0.80 0.10 0.03 0.07
## Especialización 0.72 0.22 0.03 0.03
## Maestría 0.63 0.37 0.00 0.00
scipy.stats.chi2_contingency(pd.crosstab(df[entrenamiento], df[var])) # Prueba del chi-cuadrado
## (10.734184196098798, 0.29437023229553705, 9, array([[18.28571429, 22.85714286, 24.38095238, 14.47619048],
## [ 4.34285714, 5.42857143, 5.79047619, 3.43809524],
## [ 0.68571429, 0.85714286, 0.91428571, 0.54285714],
## [ 0.68571429, 0.85714286, 0.91428571, 0.54285714]]))
sns.countplot(x=entrenamiento, hue=var, data=df, edgecolor='black') # Gráfico de barras
plt.xlabel(etiqueta)
plt.ylabel('Núm. docentes')
plt.legend(title='Grado académico', loc='upper right')
plt.show()
## vs facultad
var = 'facultad' # Definición de la variable de contraste
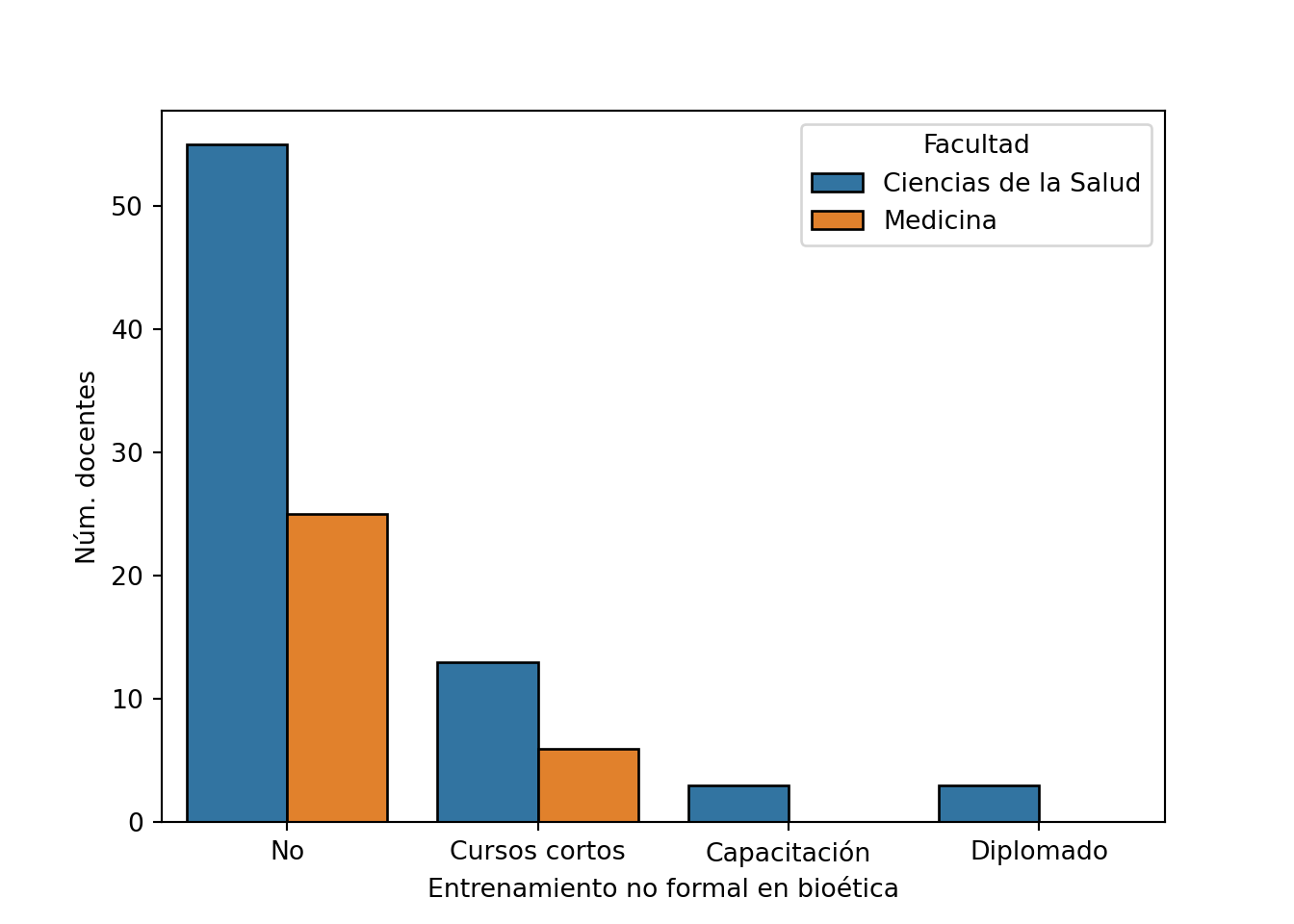
pd.crosstab(df[var], df[entrenamiento]) # Frecuencia absoluta
## no_formal No Cursos cortos Capacitación Diplomado
## facultad
## Ciencias de la Salud 55 13 3 3
## Medicina 25 6 0 0
pd.crosstab(df[var], df[entrenamiento], normalize='index').round(2) # Frecuencia relativa
## no_formal No Cursos cortos Capacitación Diplomado
## facultad
## Ciencias de la Salud 0.74 0.18 0.04 0.04
## Medicina 0.81 0.19 0.00 0.00
scipy.stats.chi2_contingency(pd.crosstab(df[entrenamiento], df[var])) # Prueba del chi-cuadrado
## (2.6666461134309176, 0.4459252278918513, 3, array([[56.38095238, 23.61904762],
## [13.39047619, 5.60952381],
## [ 2.11428571, 0.88571429],
## [ 2.11428571, 0.88571429]]))
sns.countplot(x=entrenamiento, hue=var, data=df, edgecolor='black') # Gráfico de barras
plt.xlabel(etiqueta)
plt.ylabel('Núm. docentes')
plt.legend(title='Facultad', loc='upper right')
plt.show()
## vs carrera
var = 'carrera' # Definición de la variable de contraste
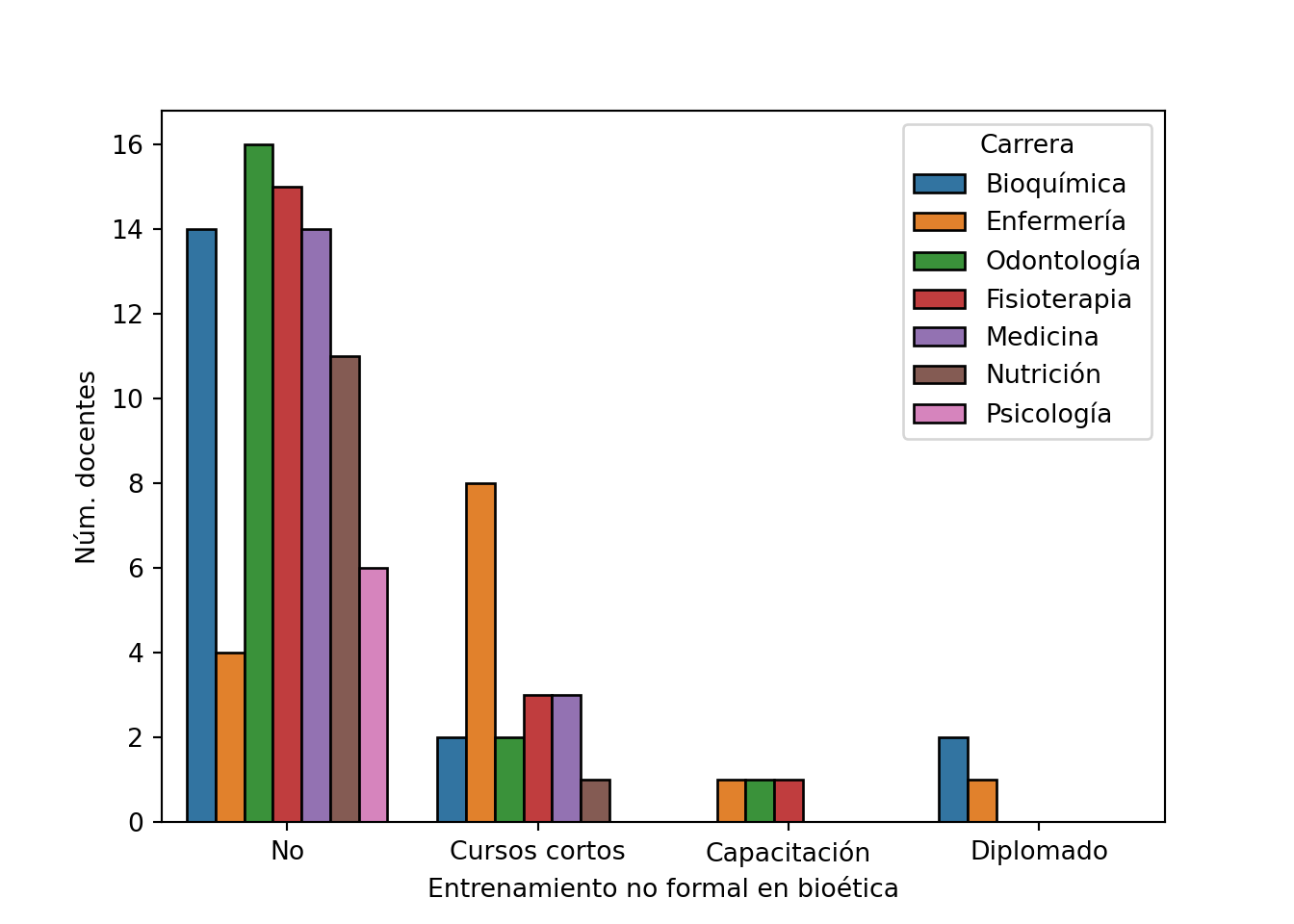
pd.crosstab(df[var], df[entrenamiento]) # Frecuencia absoluta
## no_formal No Cursos cortos Capacitación Diplomado
## carrera
## Bioquímica 14 2 0 2
## Enfermería 4 8 1 1
## Fisioterapia 15 3 1 0
## Medicina 14 3 0 0
## Nutrición 11 1 0 0
## Odontología 16 2 1 0
## Psicología 6 0 0 0
pd.crosstab(df[var], df[entrenamiento], normalize='index').round(2) # Frecuencia relativa
## no_formal No Cursos cortos Capacitación Diplomado
## carrera
## Bioquímica 0.78 0.11 0.00 0.11
## Enfermería 0.29 0.57 0.07 0.07
## Fisioterapia 0.79 0.16 0.05 0.00
## Medicina 0.82 0.18 0.00 0.00
## Nutrición 0.92 0.08 0.00 0.00
## Odontología 0.84 0.11 0.05 0.00
## Psicología 1.00 0.00 0.00 0.00
scipy.stats.chi2_contingency(pd.crosstab(df[entrenamiento], df[var])) # Prueba del chi-cuadrado
## (30.38097101144243, 0.033903228888663706, 18, array([[13.71428571, 10.66666667, 14.47619048, 12.95238095, 9.14285714,
## 14.47619048, 4.57142857],
## [ 3.25714286, 2.53333333, 3.43809524, 3.07619048, 2.17142857,
## 3.43809524, 1.08571429],
## [ 0.51428571, 0.4 , 0.54285714, 0.48571429, 0.34285714,
## 0.54285714, 0.17142857],
## [ 0.51428571, 0.4 , 0.54285714, 0.48571429, 0.34285714,
## 0.54285714, 0.17142857]]))
sns.countplot(x=entrenamiento, hue=var, data=df, edgecolor='black') # Gráfico de barras
plt.xlabel(etiqueta)
plt.ylabel('Núm. docentes')
plt.legend(title='Carrera', loc='upper right')
plt.show()
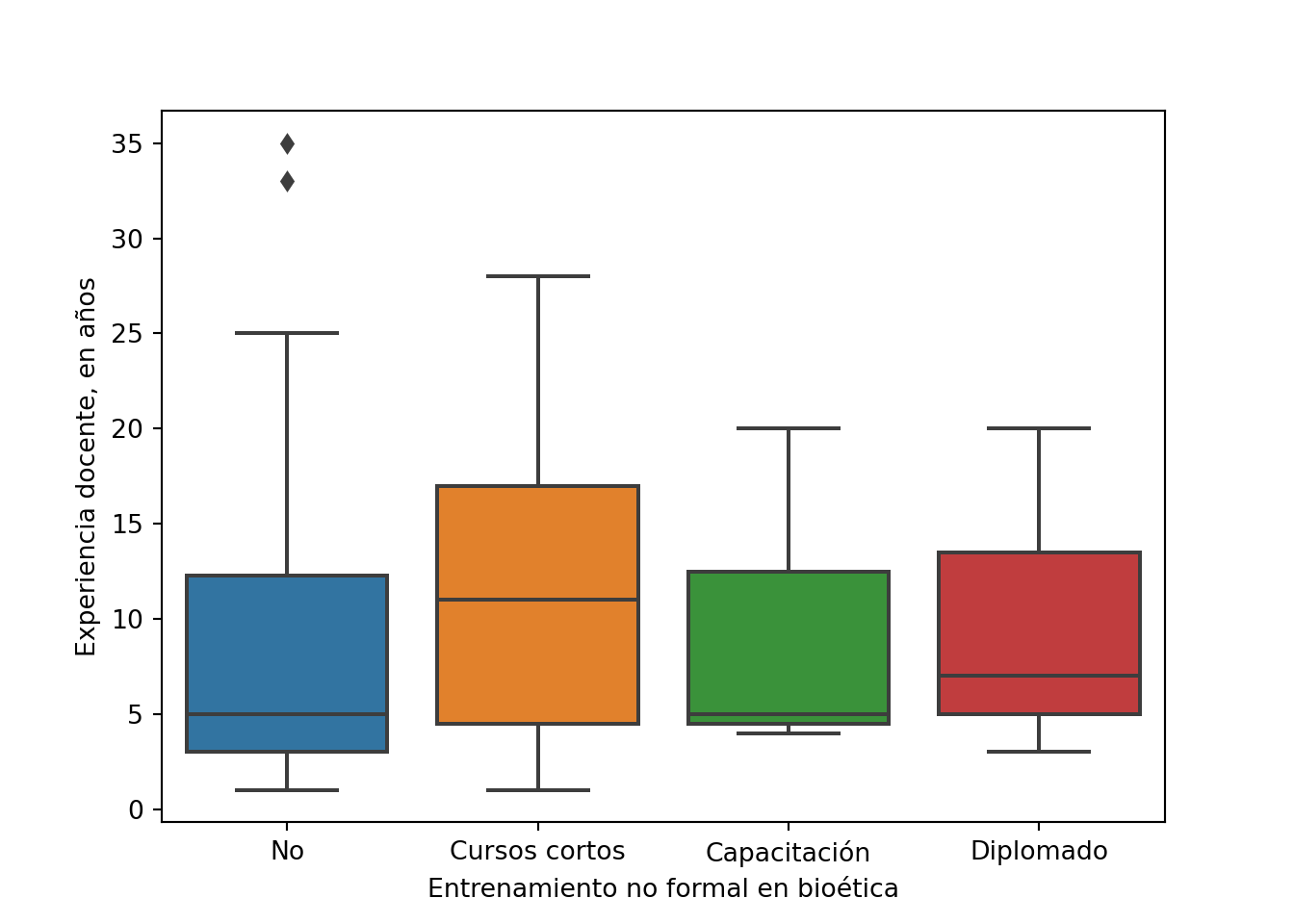
## vs experiencia docente
var = 'experiencia'
df.groupby(entrenamiento)[var].describe().round().transpose() # Tendencia central y dispersión
## no_formal No Cursos cortos Capacitación Diplomado
## count 80.0 19.0 3.0 3.0
## mean 8.0 11.0 10.0 10.0
## std 7.0 8.0 9.0 9.0
## min 1.0 1.0 4.0 3.0
## 25% 3.0 4.0 4.0 5.0
## 50% 5.0 11.0 5.0 7.0
## 75% 12.0 17.0 12.0 14.0
## max 35.0 28.0 20.0 20.0
scipy.stats.kruskal(*[data[var].values for name, data in df.groupby(entrenamiento)]) # Prueba de Kruskal-Wallis
## KruskalResult(statistic=2.7386406017078104, pvalue=0.43370061764345524)
sns.boxplot(x=entrenamiento, y=var, data =df) # Gráfico de cajas
plt.xlabel(etiqueta)
plt.ylabel('Experiencia docente, en años')
plt.show()